



















交叉信息研究院赵行课题组等提出新型符号性记忆框架ChatDB
2024/04/09
 812
812近期,清华大学交叉信息研究院赵行助理教授研究组及其合作单位的研究者们提出一种新型符号性记忆框架ChatDB,突破了此前常用的记忆框架中对储存信息操作不精确、历史信息储存形式缺乏结构性等局限。
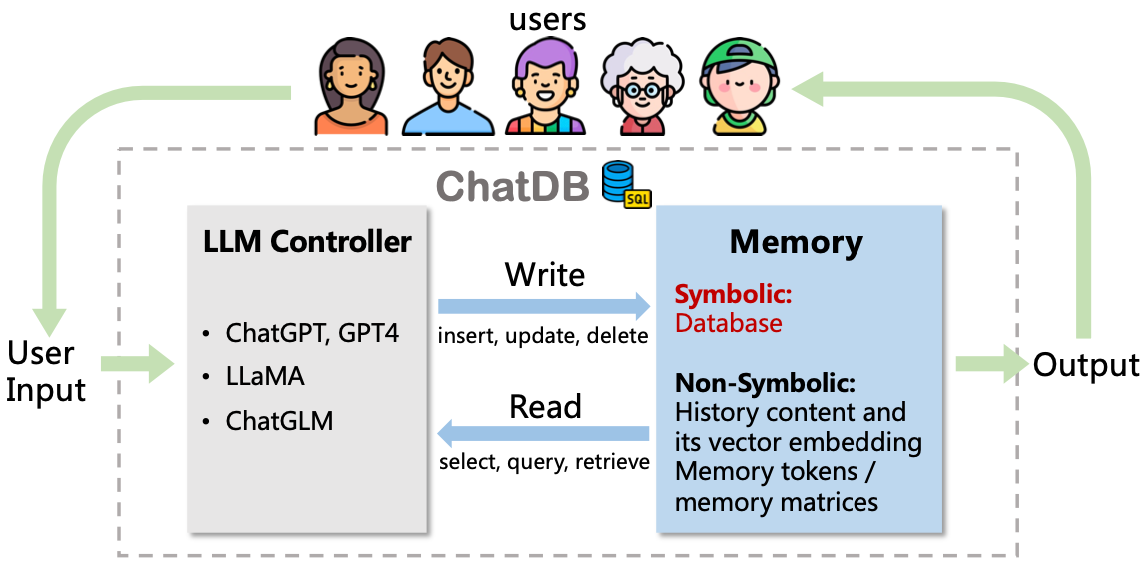
图1.ChatDB工作流程示意图
ChatDB由一个大语言模型(如ChatGPT)和一个数据库组成,可利用符号性操作(即SQL指令),实现对历史信息长期、精确的记录、处理和分析,并帮助回应用户的需求。其框架包含三个主要阶段:输入处理(input processing),记忆链(chain-of-memory),总结回复(response summary)。第一阶段,LLMs处理用户输入需求,对不涉及使用数据库记忆模块的指令,直接生成回复;而对涉及记忆模块的指令,则生成能与数据库记忆模块交互的一系列SQL语句。第二阶段,记忆链执行一系列中间记忆操作与符号性记忆模块交互。ChatDB按照先前生成的SQL语句依次执行插入、更新、选择、删除等操作。外部数据库执行相应的SQL语句,更新数据库并返回结果。在执行每一步记忆操作之前,ChatDB会根据先前SQL语句的结果决定是否更新当前记忆操作。第三阶段,语言模型综合与数据库交互得到的结果,并对用户的输入做出总结回复。
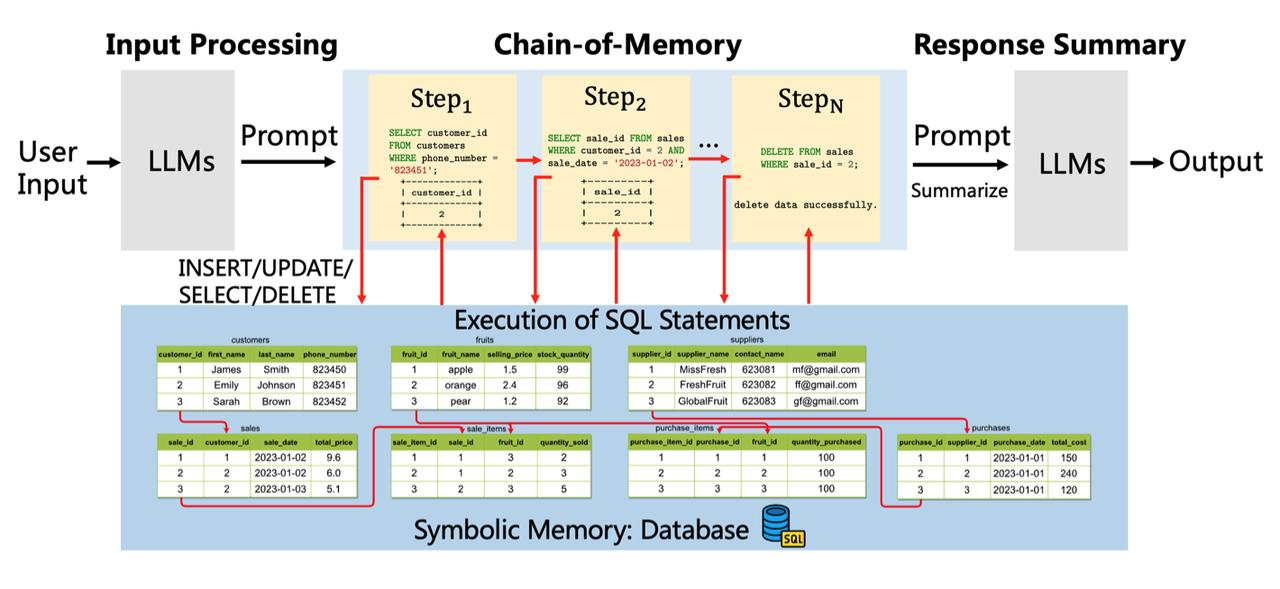
图2.ChatDB框架概览
为验证ChatDB中将数据库作为符号性记忆模块来增强大语言模型的有效性,并与其他的模型进行定量比较,研究者们构造了一家水果店运营管理的合成数据集,并命名为“水果商店数据集”,其中包含了70条按时间顺序生成的商店记录,约有3300个tokens(小于ChatGPT最大上下文窗口长度4096个)。这些记录包含水果店的四种常见操作:采购、销售、价格调整和退货。ChatDB模型中的LLM模块使用了ChatGPT(GPT-3.5 Turbo),温度参数设置为0,并使用MySQL数据库作为其外部符号性记忆模块。对比的基线模型为ChatGPT(GPT-3.5 Turbo),最大的上下文长度为4096,温度参数也设置为0。研究者们在水果商店问答数据集上进行了实验,发现相对于ChatGPT,ChatDB在这些问题的解答上展现出了显著的优势。
近日,该成果以论文“ChatDB:用数据库作为符号性记忆模块来增强大语言模型”(ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory)发布于康奈尔大学ArXiv。
该论文共同第一作者为清华大学交叉信息研究院博士生胡晨旭和智源研究院研究员付杰,通讯作者为付杰和交叉信息院助理教授赵行,其他作者包括清华大学博士生杜晨壮、骆思勉,以及浙江大学助理教授赵俊博。
文章来源清华大学新闻,分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。







-
2026年第五届机器学习、云计算与智 26

-
2026年第二届计算机视觉与机器学习 627
-
2026年6月优质国际学术会议推荐 1157
-
2026年智慧教育与数据挖掘国际学术 813
-
2026年第11届生物医学信号与图像 697
-
2026资源、化学化工与应用材料国际 2559
-
2026年图像处理与数字创意设计国际 2369
-
2026年机械工程,新能源与电气技术 6849
-
2026年材料科学、低碳技术与动力工 2524
-
2026年海洋科学、水利工程与环境管 06-18

-
2026年环境工程、材料科学与循环经 06-18
-
2026年航空动力、流体力学与热物理 06-18
-
2026年地球化学、核物理与地质学国 06-18
-
2026年微机电、物理学与建模仿真国 06-18
-
2026年机械工程、电子技术与自动化 06-18


































-
2026 JCR影响因子正式发布272
-
中国科协发布2025年《重要学术858
-
2026年新锐分区(原中科院期刊5648
-
2025年两院院士增选有效候选人5280
-
好学术:科研网址导航|学术头条分6842
-
2025年国际期刊预警名单发布!7028
-
2025年中科院期刊分区表重磅发24788
-
吉林大学校长张希:学术会议中的提8093
-
研究表明太阳耀斑终端激波可作为地06-24
-
研究揭示藻—菌共生体系强化养殖尾06-24
-
双功能手性双核镍催化研究获进展06-24
-
研究发现银河系中心极端环境下大质06-24
-
废塑料升级利用研究取得进展06-24
-
硒太阳能电池研究取得进展06-24
-
南京大学王涛团队首次发现110亿06-24
-
山东工商学院煤炭经济研究院 21395

-
中国科学院心理研究所 18299
-
北京四通博大 18283
-
张家界光明国际旅行社会议奖励旅游 19210
-
WCNIS2009组委会 23296
-
银河信息技术学院 18390
-
上海商图信息咨询有限公司 23592
-
中国科学院数学与系统科学研究院 8817
-
大连理工大学 23699
-
中国环境科学学会 24425
-
成都军区昆明总医院全军骨科中心 18304
-
北京中材企联新材料技术研究中心 23270
-
中国优生科学协会 23355
-
新天木业有限公司 18379
-
世界水土保持协会 23661
-
华北电力大学 8483
-
中国图书馆学会 22220
-
二十一世纪公益基金会 24327
-
2017教育与发展国际会议(IC 24508
-
WILL 8386



