



















清华大学生物医学交叉研究院黄牛团队开发机器学习势能模型助力高精度刻画蛋白片段非共价相互作用
2026/06/23
 17
17宏观生命活动根植于微观原子间的相互作用,其中非共价相互作用(NCI)主导着蛋白质折叠、分子识别和药物-靶点结合等核心过程。在生物计算领域,对非共价相互作用的表征往往面临或追求物理准确性或侧重运算速度的两难。经典分子力学以高效见长,但其物理近似引入了固有误差;量子力学(QM)虽能从物理本质精准求解非共价作用,却受限于高昂的计算成本与迟缓的运算速度,难以支撑蛋白质等生物体系的规模化模拟。近年来,机器学习原子间势能(MLIP)被视为有望实现精度与效率“双赢”的途径。
针对精度和效率难以兼得的痛点,清华大学生物医学交叉研究院黄牛研究员团队最新研究借鉴经典力场的迭代发展思路,采用“自底向上、分而治之”的建模策略,从基础小分子二体片段的相互作用出发,逐步构建多层次、全覆盖的二体片段非共价相互作用QM数据集,并据此研发出专为蛋白片段非共价相互作用打造的机器学习势能模型PANIP(PAirwise Non-covalent Interaction Potential)。通过引入多精度主动学习(MFAL)策略,在海量蛋白片段数据中高效筛选代表性样本,以极低的数据量实现接近量子化学级别的计算精度。
研究团队依托蛋白质数据库(PDB)开展数据集构建工作,首先筛选出29204个高分辨率蛋白结构,将蛋白质拆解为氨基酸侧链、主链结构、水分子等17类化学片段;以重原子间距2-4?为筛选标准,识别存在非共价相互作用的片段对,最终得到涵盖153种组合类型、总量高达3630万组的蛋白片段二聚体原始数据集。
如果对全部样本开展高精度量子化学标注,算力与时间成本将难以承受。为此,团队搭建了一套分层式多精度主动学习流程(图1)。先使用低成本的r2SCAN-3c量化方法完成全量样本的初步能量计算,再通过机器学习代理模型迭代识别预测误差大、信息价值高的 “关键样本”,逐步扩充训练集。最终从3630万组原始片段对中,筛选出约315万组代表性样本,构建得到PDB-FRAGID数据集。这套精简数据集仅占原始数据总量的8.7%,却完整保留了17类片段、153种片段组合的化学特征与构象多样性,覆盖氢键、静电作用、阳离子-π作用、硫基相互作用等各类蛋白典型非共价作用模式。研究团队继而采用高精度ωB97X-D3BJ/def2-TZVPP量化方法,对PDB-FRAGID数据集进行能量标注,为PANIP模型训练筑牢高质量数据基础。
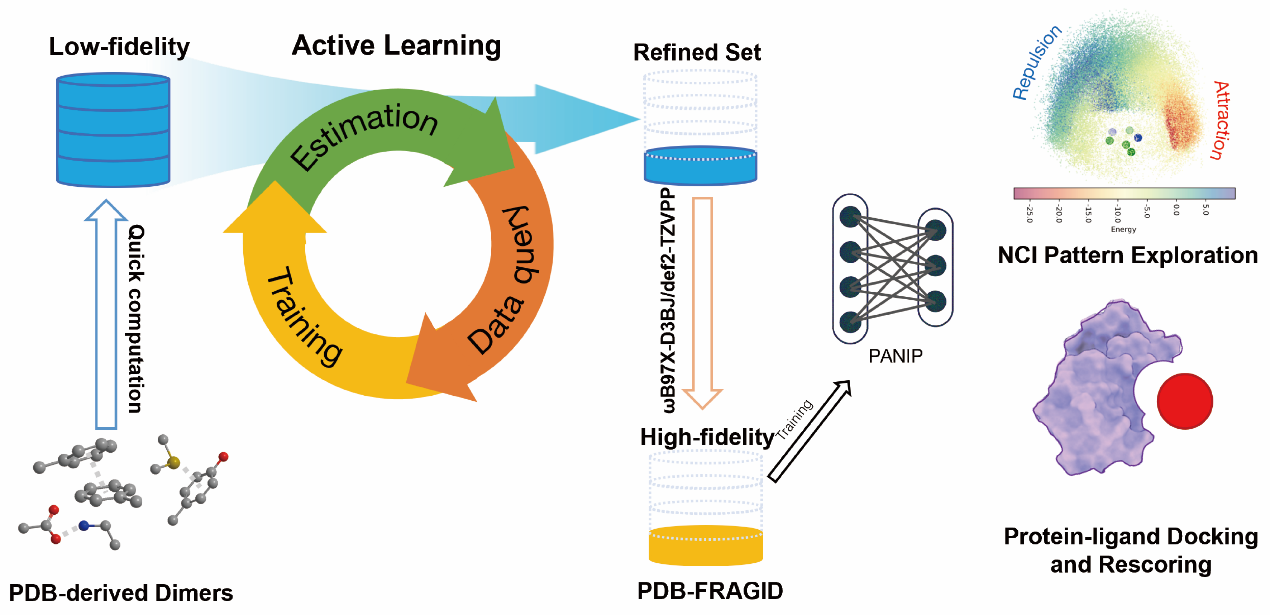
图1.训练集构建和模型训练流程
PANIP基于NequIP等变图神经网络框架搭建而成,能够精准捕捉原子空间取向带来的相互作用差异。在多套独立基准测试集上,该模型展现出优异的计算精度、构象适应性与跨体系泛化能力。第一,针对蛋白来源的平衡态片段二聚体,PANIP平均绝对误差(MAE)低至0.09kcal/mol,和高精度量子化学计算结果高度吻合。第二,在剑桥晶体数据库(CSD)来源的小分子片段、随机采样的非平衡构象等外部测试集中,PANIP依旧保持高精度输出,证明模型不局限于蛋白环境,可适配多样化分子体系。第三,与目前通用的AIMNet2机器学习势能相比,PANIP在带电体系、强相互作用二聚体、硫基相互作用等难点场景下误差大幅降低;在GMTKN55、通用分子非共价作用基准集等权威测试中,各项指标全面领先。
在计算效率层面,PANIP更是实现量级提升。相较于ωB97X-D3BJ/def2-TZVPP高精度量化计算,模型运算速度提升两个数量级以上;即便对比AIMNet2,端到端计算效率也提升约1.3倍,真正实现了量子级精度、力场级速度。
依托PANIP的高效计算能力,研究团队还完成了3630万组蛋白片段对的大规模能量解析,系统剖析了阳离子-π作用、甲硫氨酸 – 芳香环硫基作用等典型非共价作用的空间分布与能量规律,挖掘出多种此前未被充分报道的作用模式,深化了对蛋白微观相互作用机制的认知(图2)。
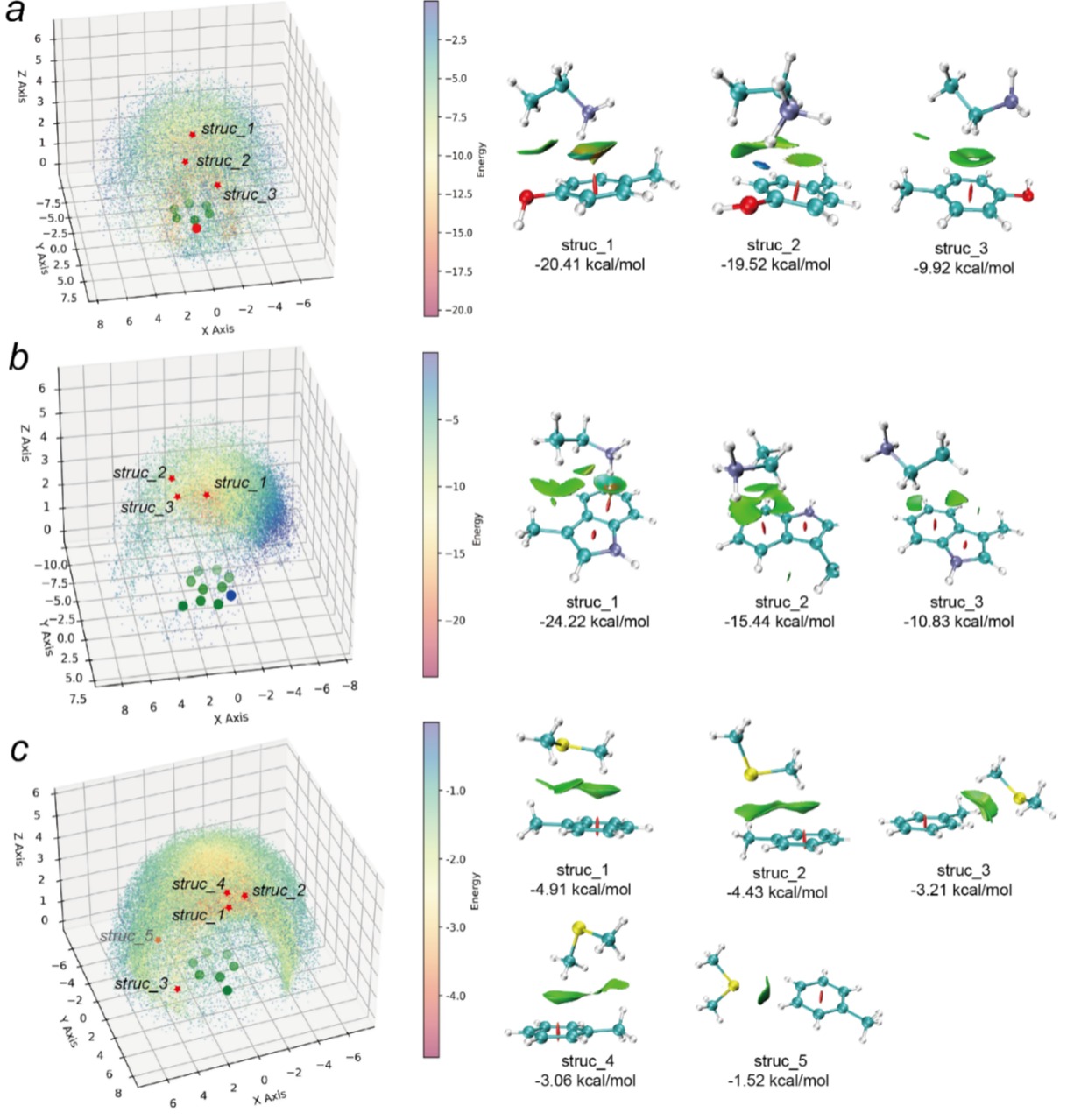
图2.ETAM PMPO(a)、ETAM MIND(b)与MBZ MSM(c)二聚体的空间分布及代表性低能结构
研究进一步拓展PANIP的应用场景,结合片段化能量分解方案,将其开发为基于片段的打分函数,应用于蛋白-配体分子对接与结合构象排序。选取T4溶菌酶突变体、丙酮酸激酶M2(PKM2)等经典模式研究体系,总计22套蛋白-配体复合物体系开展测试。结果显示,在半数测试体系中,PANIP可将晶体原生结合构象排在对接结果首位;相较于DOCK内置AMBER传统力场打分,PANIP能显著提升天然构象的排名准确率,降低最优预测构象的原子均方根偏差(RMSD)。
该工作在方法学上,验证了多精度主动学习是解决大规模生物分子数据冗余、平衡标注成本与模型性能的高效路径,为同类机器学习势能模型的开发提供了标准化范式。在应用层面,PANIP提升了蛋白专属高精度机器学习势能的建模能力,为蛋白质工程、分子互作机制解析、先导化合物筛选等研究提供了低成本、高精度的计算工具。未来,这套工具有望和经典力场、通用机器学习模型形成互补,为生物分子模拟、计算药物研发领域向 “高精度、高效率、规模化”方向持续发展打通“最后一公里”。
研究成果以“开发一种用于描述蛋白质中非共价相互作用的机器学习原子间势函数”(Developing a machine-learning interatomic potential for non-covalent interactions in proteins)为题,于6月8日发表于《数字发现》(Digital Discovery)。
清华大学生物医学交叉研究院黄牛实验室2020级博士生曾乐嘉为论文第一作者,清华大学生物医学交叉研究院研究员黄牛为论文通讯作者。
研究得到北京市科学技术委员会、中关村科技园区管理委员会、清华大学的资助,全部研究工作在清华大学生物医学交叉研究院完成。
文章来源清华大学,分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。







-
2026年第五届机器学习、云计算与智 26

-
2026年第二届计算机视觉与机器学习 627
-
2026年6月优质国际学术会议推荐 1157
-
2026年智慧教育与数据挖掘国际学术 813
-
2026年第11届生物医学信号与图像 697
-
2026资源、化学化工与应用材料国际 2559
-
2026年图像处理与数字创意设计国际 2369
-
2026年机械工程,新能源与电气技术 6849
-
2026年材料科学、低碳技术与动力工 2524
-
2026年海洋科学、水利工程与环境管 06-18

-
2026年环境工程、材料科学与循环经 06-18
-
2026年航空动力、流体力学与热物理 06-18
-
2026年地球化学、核物理与地质学国 06-18
-
2026年微机电、物理学与建模仿真国 06-18
-
2026年机械工程、电子技术与自动化 06-18


































-
2026 JCR影响因子正式发布272
-
中国科协发布2025年《重要学术858
-
2026年新锐分区(原中科院期刊5648
-
2025年两院院士增选有效候选人5280
-
好学术:科研网址导航|学术头条分6842
-
2025年国际期刊预警名单发布!7028
-
2025年中科院期刊分区表重磅发24788
-
吉林大学校长张希:学术会议中的提8093
-
研究表明太阳耀斑终端激波可作为地06-24
-
研究揭示藻—菌共生体系强化养殖尾06-24
-
双功能手性双核镍催化研究获进展06-24
-
研究发现银河系中心极端环境下大质06-24
-
废塑料升级利用研究取得进展06-24
-
硒太阳能电池研究取得进展06-24
-
南京大学王涛团队首次发现110亿06-24
-
北京语言大学理论语言学研究中心 23357

-
人大办公厅老干部处 18388
-
湖南警察学院 18573
-
武汉华联帕博文化传播有限公司 23485
-
中国医药教育协会培训部 2463
-
电子科技大学计算机学院国家级计算 2580
-
西北工业大学 23539
-
西昌学院农学系 18427
-
云南水富云天化股份公司 18301
-
广医三院 21681
-
点时文化传媒(北京)有限公司 8388
-
HKSME 23867
-
中国工业微生物菌种保藏管理中心 8527
-
IETP 2377
-
香港机械工程师协会 2313
-
2017第二届国际土地复垦与生态 24410
-
国际工学技术出版协会 8430
-
昆明全昌会议服务有限公司 23472
-
华北电力大学 21562
-
淄博友好美容整形医院 18384



