



















人工智能研究院朱毅鑫及合作者在赋予AI语言理解和场景感知能力,实现目标导向的室内人体运动生成方向取得重要进展
2024/04/15
 812
812近日,人工智能研究院朱毅鑫助理教授课题组在NeruIPS发表论文“HUMANISE: Language-conditioned Human Motion Generation in 3D Scenes”,提出了一个大规模且具有丰富语义标注的HSI数据集,即HUMANISE。并且开启了一项新任务,即三维场景中语言约束下的人体运动序列生成。论文进一步设计了一个场景和语言约束的运动生成模型,该模型能够生成多样且语义一致的室内人体运动。
在现实生活中,人可以根据语言指令轻松地执行相应动作,并与场景中物体进行合理交互,如图1所示。在虚拟环境中,如果以同样的方式给虚拟人目标,让其与室内场景进行交互,虚拟人则需要同时具备语言理解、场景感知、以及运动生成的能力。在以往的研究工作中,人体运动生成(Human Motion Generation)是指通过生成模型(Generative Model)产生真实且多样的人体动作序列,在VR/AR、游戏人物动画等方面具有巨大的应用价值。与以往研究不同,本文着重于对目标导向的室内人体运动生成进行研究,这对于人-场景交互(Human-Scene Interaction, HSI)[1,2,3],场景可供性(Affordance)[4] 等相关研究领域具有重要意义。

图1 根据语言指令与场景交互
目标导向的室内人体运动生成是指虚拟人依据语言描述的目标在室内场景中生成相应的运动序列。想象一下,假设虚拟人接受了“sit on the armchair near the desk”的指令,如果虚拟人要完成这一任务,他需要首先理解指令的语义并感知周围环境,才能生成与语言描述一致的人体运动序列。然而,受限于现有HSI 数据集[1,2]的规模和质量,以及缺少相应的语义标注,学习在三维场景中生成以目标为导向且具有多样性的人体运动序列是极具挑战性的任务。
为解决上述问题,本文首先提出了一个大规模、且具有丰富语义标注的合成HSI数据集——HUMANISE。该数据集共包括在643个不同的三维场景中的19.6k段运动序列,总帧数达1.2M帧。基于该数据集,本文尝试解决三维场景中语言约束下的人体运动序列生成这样一个新的任务,旨在生成合理、多样、具有指定动作类型和交互对象的人体运动序列。然而,该任务相比于此前的人体运动生成任务更加困难,主要包括三方面原因:
•三维场景和语言描述同时对人体运动生成构成了约束,需要模型对多模态信息有一个全面的理解;
•生成的人体运动序列需要精确地在目标位置附近执行正确的动作;
•生成的人体运动序列需要同时具备真实性和合理性。
同时,本文基于cVAE[5]框架,结合两个辅助任务,设计了一个新颖的生成模型。定性和定量实验结果表明,该模型能够在三维场景中生成语义一致的多样性人体运动序列。
本文构建合成HUMANISE数据集的核心思想是自动地将动捕得到的人体运动序列(即,AMASS[6])与三维室内场景(即,ScanNet[7])“对齐”。具体而言,对于一段具有特定动作的运动序列(例如,sit),首先在场景中选择可能的交互物体(例如,armchair),同时对交互物体表面可能的交互位置进行采样。之后,通过使用碰撞(collision)和接触(contact)约束对有效的平移和旋转参数进行采样,从而使得平移旋转后的人体和场景之间的交互在物理上合理、且视觉效果上自然。同时,我们参考Sr3D[8]使用基于模板的语言描述自动对合成运动序列进行标注。
最终,合成的HUMANISE数据集包括四种不同类别的动作,即“walk”“sit”,“stand up” 和“lie down”。图2和图3分别展示了HUMANISE数据集中的部分数据预览以及部分渲染动画。

图2 HUMANISE数据集预览

图3 HUMANISE部分数据的渲染动画
基于HUMANISE数据集,本文提出了一个新的生成任务——三维场景中语言约束下的人体运动序列生成。具体而言,给定一个三维场景和一段语言描述,其目标是生成真实且多样的人体运动序列,同时该运动序列需要满足与语言描述一致、在三维场景中合理。

图4 三维场景中语言约束的人体运动生成
为此,本文构建了一个基于cVAE框架的生成模型,该模型使用两个Encoder分别对输入的场景和语言进行编码,并使用自注意力机制融合这两个不同模态的信息以生成条件嵌入(conditional embedding)。该模型使用循环神经网络对输入的运动序列进行编码,并使用Transformer Decoder进行解码以输出人体运动序列。本文进一步设计了两个辅助损失函数,分别用于定位目标物体和识别动作类别。定性和定量的实验结果表明,本文所提出的模型能够在给定三维场景中生成具有多样性、且与语言指令语义一致的人体运动序列,并且在各种评价指标上优于基线方法。
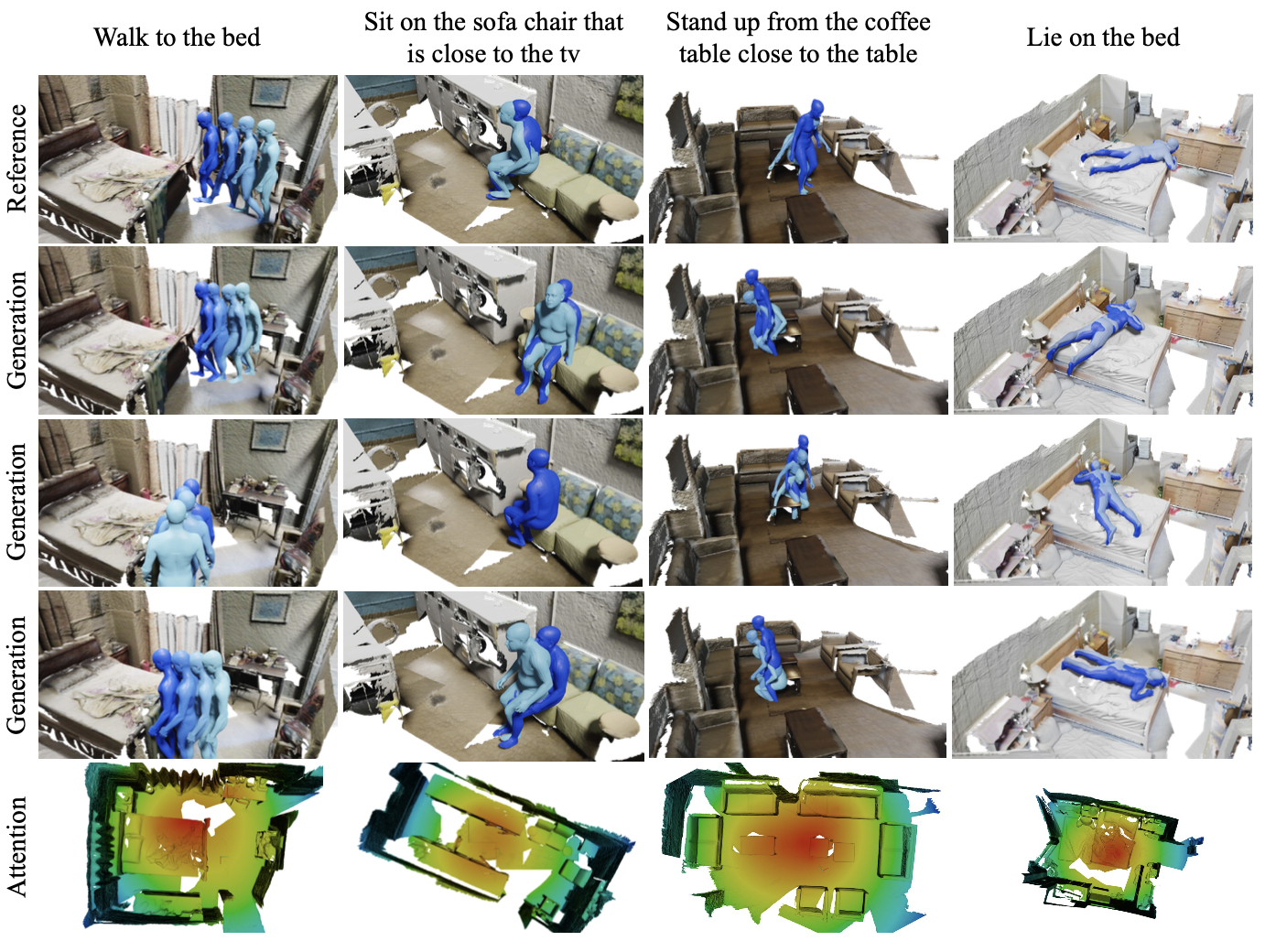
图5 定性可视化实验结果

图6 定量实验结果
图7的消融实验结果表明,在没有辅助损失函数的情况下,模型很难生成指定的动作以及定位到指定的交互物体,而完整模型能够更好地帮助模型识别语言所描述的动作类别以及目标交互物体。

图7 消融实验
在这项工作中,本文提出了一个大规模且具有丰富语义标注的HSI数据集,即HUMANISE。它包含各种各样的、在物理上合理的人-场景交互运动序列,同时每段运动序列都标注有相应的语言描述标注。HUMANISE开启了一项新任务,即三维场景中语言约束下的人体运动序列生成。本文进一步设计了一个场景和语言约束的运动生成模型,该模型能够生成多样且语义一致的室内人体运动。
本文作者为王赞(北京理工大学/北京通用人工智能研究院)、陈以新(北京通用人工智能研究院)、刘腾宇(北京通用人工智能研究院),通讯作者为朱毅鑫(北京大学)、梁玮(北京理工大学/北京理工大学长三角研究院)、黄思远(北京通用人工智能研究院)。
参考文献:
[ 1 ] Hassan, Mohamed, et al. "Resolving 3D human pose ambiguities with 3D scene constraints." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[ 2 ] Cao, Zhe, et al. "Long-term human motion prediction with scene context." European Conference on Computer Vision. 2020.
[ 3 ] Chen, Yixin, et al. "Yourefit: Embodied reference understanding with language and gesture." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[ 4 ] Xu, Chao, et al. "PartAfford: Part-level Affordance Discovery from 3D Objects." arXiv preprint arXiv:2202.13519. 2022.
[ 5 ] Sohn, Kihyuk, Honglak Lee, and Xinchen Yan. "Learning structured output representation using deep conditional generative models." Advances in Neural Information Processing Systems. 2015.
[ 6 ] Mahmood, Naureen, et al. "AMASS: Archive of motion capture as surface shapes." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[ 7 ] Dai, Angela, et al. "Scannet: Richly-annotated 3d reconstructions of indoor scenes." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[ 8 ]Achlioptas, Panos, et al. "Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes." European Conference on Computer Vision. 2020.
文章来源北京大学新闻网,分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。







-
2026年第五届机器学习、云计算与智 26

-
2026年第二届计算机视觉与机器学习 627
-
2026年6月优质国际学术会议推荐 1157
-
2026年智慧教育与数据挖掘国际学术 813
-
2026年第11届生物医学信号与图像 697
-
2026资源、化学化工与应用材料国际 2559
-
2026年图像处理与数字创意设计国际 2369
-
2026年机械工程,新能源与电气技术 6849
-
2026年材料科学、低碳技术与动力工 2524
-
2026年海洋科学、水利工程与环境管 06-18

-
2026年环境工程、材料科学与循环经 06-18
-
2026年航空动力、流体力学与热物理 06-18
-
2026年地球化学、核物理与地质学国 06-18
-
2026年微机电、物理学与建模仿真国 06-18
-
2026年机械工程、电子技术与自动化 06-18


































-
2026 JCR影响因子正式发布272
-
中国科协发布2025年《重要学术858
-
2026年新锐分区(原中科院期刊5648
-
2025年两院院士增选有效候选人5280
-
好学术:科研网址导航|学术头条分6842
-
2025年国际期刊预警名单发布!7028
-
2025年中科院期刊分区表重磅发24788
-
吉林大学校长张希:学术会议中的提8093
-
研究表明太阳耀斑终端激波可作为地06-24
-
研究揭示藻—菌共生体系强化养殖尾06-24
-
双功能手性双核镍催化研究获进展06-24
-
研究发现银河系中心极端环境下大质06-24
-
废塑料升级利用研究取得进展06-24
-
硒太阳能电池研究取得进展06-24
-
南京大学王涛团队首次发现110亿06-24
-
湖北研学博科文化传播有限公司 24344

-
沈阳航空工业学院 23490
-
华中科技大学 21579
-
中南民族大学 24527
-
广东省广州市辉煌大酒店 18433
-
2018 Internation 21495
-
国际包豪斯科学出版社 21475
-
有你相伴(北京)信息技术有限公司 24333
-
凯盛投资咨询有限公司 24412
-
世博威(上海)展览有限公司 2535
-
中南林业科技大学 2446
-
百奥泰国际会议(大连)有限公司 21309
-
《电子测量与仪器学报》杂志社 23713
-
上海东篱信息科技有限公司 8361
-
中国连锁经营协会 21442
-
中国系统仿真协会 23608
-
南昌明月风光会展服务有限公司 18261
-
哈尔滨工业大学 2449
-
重庆交通大学管理学院 21463
-
东吴期货有限公司 18444



