



















人工智能研究院朱毅鑫助理教授及合作者在支持机器进行词汇学习和更广泛的人类学习工作中取得进展
2023/12/05
 798
798近日,北京大学人工智能研究院朱毅鑫助理教授及合作者在ICML 2023发表题为“MEWL:Few-shot multimodal word learning with referential uncertainty”的研究论文。该研究通过在机器中设计词汇学习任务来评估机器在与人类相同的条件下学习词汇的能力。MEWL简单直观,支持词汇学习和更广泛的人类学习中的这些基本元素。
学习单词和语言是人类认知发展中最基本的阶段之一,它为后续的其他关键能力奠定了基础。了解人类学习词汇的模式对构建能够像人类一样学习和推理的机器至关重要。尽管机器的语言训练研究已经取得一定进展,模型是否以类人的方式获取词义还未可知。从人类的单词学习方法中汲取灵感,研究团队构建了MEWL(MachinE Word Learning),来评估机器如何在视觉场景中学习单词和概念。为了全面评估人类和机器之间的对齐,研究团队为MEWL设计了9种任务,涵盖了交叉情境学习、引导学习和语用单词学等各种单词学习方法:形状(shape)、颜色(color)、材料(material)、物体(object)、复合(composite)、关系(relation)、自举(bootstrap)、数字(number)和语用(pragmatic)。
为了探索人类的单词学习模式在人工智能模型的中的表现,研究团队在将MEWL表达为一个少样本的视觉-语言学习问题的前提下,选择了两大类模型:多模态(视觉-语言)和单模态(纯语言)模型;同时,评估人类被试,以提供人类平均水平的对照。对于多模态模型,选取CLIP、Flamingo-1.1B和Aloe;对于纯语言模型,选取GPT-3.5和BERT。首先,使用特定任务的先知(Oracle)标注器来解析输入的视觉场景,生成一个场景描述。接下来,研究团队使用语言模型将结果分类为多项选择问题。值得注意的是,这些标注被注入了精确需要解决这些任务的归纳偏置(inductive biases),比在多模态模型中使用的图像具有更少的不确定性和模糊性。这种设计大大简化了任务难度,因为对单模态模型来说,将标注中的句法模式映射到答案更容易。

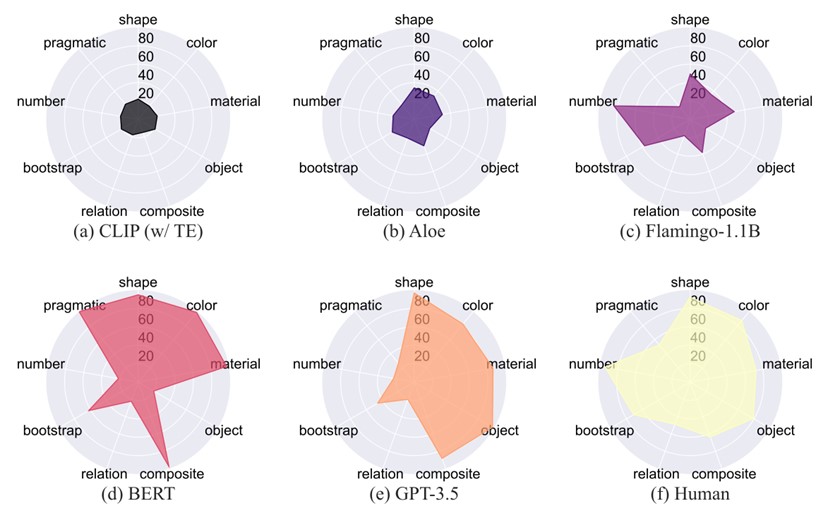
基准模型和人类在MEWL上的表现
数据显示,最好的视觉-语言模型是Flamingo-1.1B(41.0%),只有人类(73.2%)能力的大约一半。与此同时,带有CLIP特征的普通Transformer模型在所有任务上的表现只能达到随机水平(不到20%)。Aloe的以物体为中心(object-centric)的表示有助于提高性能至26.8%,但由于模型容量有限和缺乏预训练,可能会表现得更差。深入观察和分析研究结果可以发现,视觉-语言预训练模型在基本属性命名任务(即形状、颜色、材料)上表现相对良好,但无法推广到对象关系和利用语用线索进行推理。一个有趣的观察是,Flamingo模型可以解决一小部分自举任务和一些数字任务。这个结果可能归因于Flamingo模型基于语言模型,捕获句法线索并理解熟悉的词以自举单词学习。
对于单模态语言模型,微调后的BERT具有最佳的整体性能,平均性能为68.3%。BERT和GPT-3.5在对象级任务(即形状、颜色、材料、对象、复合、自举)上都表现出色,但在需要理解超越一对一映射的更复杂关系的任务上失败(即关系、数字)。在训练集上进行微调,BERT模型在实用任务上也表现良好,而GPT-3.5(未经微调)则失败,表明某些能力确实可以通过任务特定的微调来学习。带有真实文本标注(caption)的基于文本的模型通常优于基于视觉输入的模型,这一结果与人类多模态学习的经验观察和计算研究形成对比,后者认为多模态可以提升词汇和概念的获取。
为什么在少样本单词学习中,单模态模型优于多模态模型呢?
首先,单模态语言模型中的部分概念,而不是全部,可能以与人类不同的方式获取。GPT-3.5成功地在一些基本属性命名任务(即颜色、材料、形状、对象和复合)上取得了可比的性能,但却未能学习复杂的关系词(即数字、关系),表明它已经从单模态训练中获取了一些关于形状、颜色和材料的概念知识,却未能通过语用线索进行学习。其次,MEWL的单模态版本类似于一个文本翻译问题。由于我们使用专门为每个任务设计的真实文本标注(caption),单模态语言模型不需要像人类通过概念归纳(concept induction)进行原版的单词学习。相反,他们通过从熟悉的英语词汇进行少样本翻译来获取新词的含义,大大降低了多模态单词学习的难度和模糊性。最后,基于217个有效的人类回答样本,MEWL反映了人类用于单词学习的核心认知技能,为MEWL上应展示的人类级单词学习提供了重要参考。
虽然人类的单词学习模式是否应该是多模态AI的一种路径仍然是一个争论的问题,但它是人类-AI对齐的基本能力。人类使用交叉情境信息来支持少次学习的词汇和概念,而目前的机器模型却在此遭遇困难;人类通过教学和社会语用线索学习,而人工智能目前无法理解。在弥合这个差距之前,如何评估机器在与人类相同的条件下学习词汇的能力呢?研究团队利用简单直观的MEWL,通过在机器中设计单词学习任务,迈出了探索的第一步。
北京大学通用人工智能实验班2020级学生姜广源为本文第一作者,姜广源、朱毅鑫、北京通用人工智能研究院张驰研究员为本文共同通讯作者,合作作者还有北京通用人工智能研究院徐满杰研究员、辛世计研究员、北京理工大学梁玮教授、北京大学心理与认知科学学院彭玉佳助理教授。
文章来源北京大学新闻网,分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。







-
2026年第五届机器学习、云计算与智 26

-
2026年第二届计算机视觉与机器学习 627
-
2026年6月优质国际学术会议推荐 1157
-
2026年智慧教育与数据挖掘国际学术 813
-
2026年第11届生物医学信号与图像 697
-
2026资源、化学化工与应用材料国际 2559
-
2026年图像处理与数字创意设计国际 2369
-
2026年机械工程,新能源与电气技术 6849
-
2026年材料科学、低碳技术与动力工 2524
-
2026年海洋科学、水利工程与环境管 06-18

-
2026年环境工程、材料科学与循环经 06-18
-
2026年航空动力、流体力学与热物理 06-18
-
2026年地球化学、核物理与地质学国 06-18
-
2026年微机电、物理学与建模仿真国 06-18
-
2026年机械工程、电子技术与自动化 06-18


































-
2026 JCR影响因子正式发布272
-
中国科协发布2025年《重要学术858
-
2026年新锐分区(原中科院期刊5648
-
2025年两院院士增选有效候选人5280
-
好学术:科研网址导航|学术头条分6842
-
2025年国际期刊预警名单发布!7028
-
2025年中科院期刊分区表重磅发24788
-
吉林大学校长张希:学术会议中的提8093
-
研究表明太阳耀斑终端激波可作为地06-24
-
研究揭示藻—菌共生体系强化养殖尾06-24
-
双功能手性双核镍催化研究获进展06-24
-
研究发现银河系中心极端环境下大质06-24
-
废塑料升级利用研究取得进展06-24
-
硒太阳能电池研究取得进展06-24
-
南京大学王涛团队首次发现110亿06-24
-
湖北学而升文化传播有限公司 8279

-
广东瑞图万方科技优先公司 18281
-
武汉博森学术交流有限公司 8748
-
拉萨旭日会议服务有限公司 21337
-
中华两岸经文化贸繁荣促进会北京办 18323
-
深圳市汉威展览策划有限公司 18311
-
四川省自然天堂茶业有限公司 18441
-
武汉工程大学 21361
-
香港维科 2498
-
全国卫生产业企业管理协会抗菌产业 23319
-
清华大学出版社 21338
-
昆明兴达会议 24528
-
上海蓝海国际大酒店 21347
-
南方电网深圳供电局 2333
-
hksme 21528
-
中国电子商会信息工程测试专委会 3772
-
哈工大 2460
-
北京伊诺永明公关策划有限公司 23369
-
清华设计院文化遗产保护中心洞天福 24503
-
上海电子信息 23564



