















人工智能研究院朱毅鑫及合作者在赋予AI语言理解和场景感知能力,实现目标导向的室内人体运动生成方向取得重要进展
2024/04/15
 473
473近日,人工智能研究院朱毅鑫助理教授课题组在NeruIPS发表论文“HUMANISE: Language-conditioned Human Motion Generation in 3D Scenes”,提出了一个大规模且具有丰富语义标注的HSI数据集,即HUMANISE。并且开启了一项新任务,即三维场景中语言约束下的人体运动序列生成。论文进一步设计了一个场景和语言约束的运动生成模型,该模型能够生成多样且语义一致的室内人体运动。
在现实生活中,人可以根据语言指令轻松地执行相应动作,并与场景中物体进行合理交互,如图1所示。在虚拟环境中,如果以同样的方式给虚拟人目标,让其与室内场景进行交互,虚拟人则需要同时具备语言理解、场景感知、以及运动生成的能力。在以往的研究工作中,人体运动生成(Human Motion Generation)是指通过生成模型(Generative Model)产生真实且多样的人体动作序列,在VR/AR、游戏人物动画等方面具有巨大的应用价值。与以往研究不同,本文着重于对目标导向的室内人体运动生成进行研究,这对于人-场景交互(Human-Scene Interaction, HSI)[1,2,3],场景可供性(Affordance)[4] 等相关研究领域具有重要意义。

图1 根据语言指令与场景交互
目标导向的室内人体运动生成是指虚拟人依据语言描述的目标在室内场景中生成相应的运动序列。想象一下,假设虚拟人接受了“sit on the armchair near the desk”的指令,如果虚拟人要完成这一任务,他需要首先理解指令的语义并感知周围环境,才能生成与语言描述一致的人体运动序列。然而,受限于现有HSI 数据集[1,2]的规模和质量,以及缺少相应的语义标注,学习在三维场景中生成以目标为导向且具有多样性的人体运动序列是极具挑战性的任务。
为解决上述问题,本文首先提出了一个大规模、且具有丰富语义标注的合成HSI数据集——HUMANISE。该数据集共包括在643个不同的三维场景中的19.6k段运动序列,总帧数达1.2M帧。基于该数据集,本文尝试解决三维场景中语言约束下的人体运动序列生成这样一个新的任务,旨在生成合理、多样、具有指定动作类型和交互对象的人体运动序列。然而,该任务相比于此前的人体运动生成任务更加困难,主要包括三方面原因:
•三维场景和语言描述同时对人体运动生成构成了约束,需要模型对多模态信息有一个全面的理解;
•生成的人体运动序列需要精确地在目标位置附近执行正确的动作;
•生成的人体运动序列需要同时具备真实性和合理性。
同时,本文基于cVAE[5]框架,结合两个辅助任务,设计了一个新颖的生成模型。定性和定量实验结果表明,该模型能够在三维场景中生成语义一致的多样性人体运动序列。
本文构建合成HUMANISE数据集的核心思想是自动地将动捕得到的人体运动序列(即,AMASS[6])与三维室内场景(即,ScanNet[7])“对齐”。具体而言,对于一段具有特定动作的运动序列(例如,sit),首先在场景中选择可能的交互物体(例如,armchair),同时对交互物体表面可能的交互位置进行采样。之后,通过使用碰撞(collision)和接触(contact)约束对有效的平移和旋转参数进行采样,从而使得平移旋转后的人体和场景之间的交互在物理上合理、且视觉效果上自然。同时,我们参考Sr3D[8]使用基于模板的语言描述自动对合成运动序列进行标注。
最终,合成的HUMANISE数据集包括四种不同类别的动作,即“walk”“sit”,“stand up” 和“lie down”。图2和图3分别展示了HUMANISE数据集中的部分数据预览以及部分渲染动画。

图2 HUMANISE数据集预览

图3 HUMANISE部分数据的渲染动画
基于HUMANISE数据集,本文提出了一个新的生成任务——三维场景中语言约束下的人体运动序列生成。具体而言,给定一个三维场景和一段语言描述,其目标是生成真实且多样的人体运动序列,同时该运动序列需要满足与语言描述一致、在三维场景中合理。

图4 三维场景中语言约束的人体运动生成
为此,本文构建了一个基于cVAE框架的生成模型,该模型使用两个Encoder分别对输入的场景和语言进行编码,并使用自注意力机制融合这两个不同模态的信息以生成条件嵌入(conditional embedding)。该模型使用循环神经网络对输入的运动序列进行编码,并使用Transformer Decoder进行解码以输出人体运动序列。本文进一步设计了两个辅助损失函数,分别用于定位目标物体和识别动作类别。定性和定量的实验结果表明,本文所提出的模型能够在给定三维场景中生成具有多样性、且与语言指令语义一致的人体运动序列,并且在各种评价指标上优于基线方法。
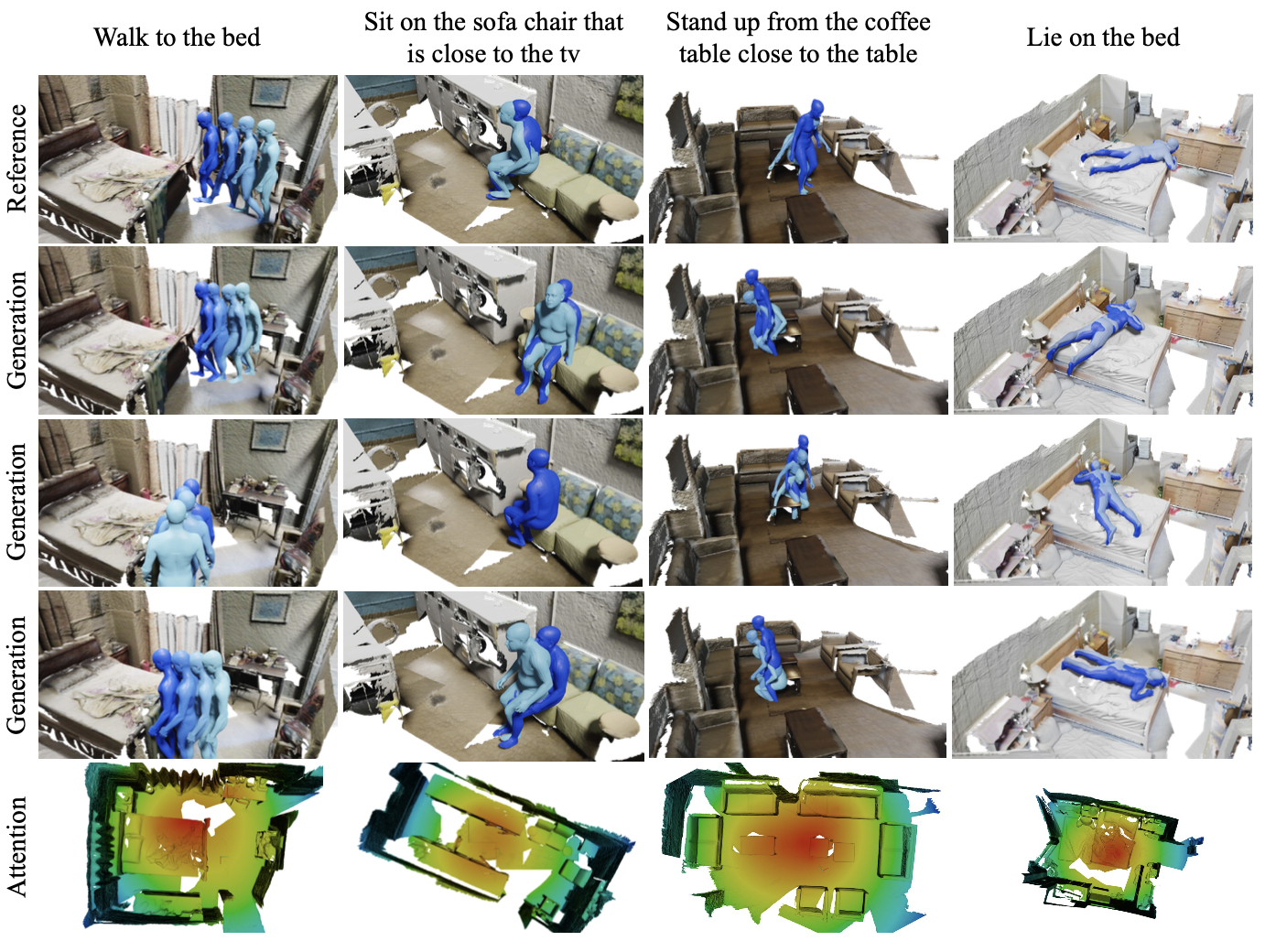
图5 定性可视化实验结果

图6 定量实验结果
图7的消融实验结果表明,在没有辅助损失函数的情况下,模型很难生成指定的动作以及定位到指定的交互物体,而完整模型能够更好地帮助模型识别语言所描述的动作类别以及目标交互物体。

图7 消融实验
在这项工作中,本文提出了一个大规模且具有丰富语义标注的HSI数据集,即HUMANISE。它包含各种各样的、在物理上合理的人-场景交互运动序列,同时每段运动序列都标注有相应的语言描述标注。HUMANISE开启了一项新任务,即三维场景中语言约束下的人体运动序列生成。本文进一步设计了一个场景和语言约束的运动生成模型,该模型能够生成多样且语义一致的室内人体运动。
本文作者为王赞(北京理工大学/北京通用人工智能研究院)、陈以新(北京通用人工智能研究院)、刘腾宇(北京通用人工智能研究院),通讯作者为朱毅鑫(北京大学)、梁玮(北京理工大学/北京理工大学长三角研究院)、黄思远(北京通用人工智能研究院)。
参考文献:
[ 1 ] Hassan, Mohamed, et al. "Resolving 3D human pose ambiguities with 3D scene constraints." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[ 2 ] Cao, Zhe, et al. "Long-term human motion prediction with scene context." European Conference on Computer Vision. 2020.
[ 3 ] Chen, Yixin, et al. "Yourefit: Embodied reference understanding with language and gesture." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[ 4 ] Xu, Chao, et al. "PartAfford: Part-level Affordance Discovery from 3D Objects." arXiv preprint arXiv:2202.13519. 2022.
[ 5 ] Sohn, Kihyuk, Honglak Lee, and Xinchen Yan. "Learning structured output representation using deep conditional generative models." Advances in Neural Information Processing Systems. 2015.
[ 6 ] Mahmood, Naureen, et al. "AMASS: Archive of motion capture as surface shapes." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[ 7 ] Dai, Angela, et al. "Scannet: Richly-annotated 3d reconstructions of indoor scenes." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[ 8 ]Achlioptas, Panos, et al. "Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes." European Conference on Computer Vision. 2020.
文章来源北京大学新闻网,分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。







-
2025年智能光子学与应用技术国际学 06-10

-
2025年8月优质学术会议推荐 589

-
2025年第十二届能源与环境研究国际 400
-
2025年机械工程,新能源与电气技术 559
-
2025年计算机科学、图像分析与信号 553
-
2025年材料化学与燃料电池技术国际 493
-
第七届精神病学国际大会(CP 202 08-01
-
第七届老龄化与老年医学国际学术会议( 08-01
-
第十四届心理学与健康国际学术研讨会( 08-01
-
第七届测绘与地理信息国际研讨会(CS 08-01
-
第七届大气与海洋科学国际研讨会(SA 08-01
-
第十一届地质灾害研究与防治国际学术会 08-01
-
第十六届地质和地球物理学国际会议(I 08-01
-
第七届细胞科学与再生医学国际研讨会( 08-01
-
第七届合成生物学与生物医学国际研讨会 08-01




































-
2025最新JCR分区及影响因子1939
-
好学术:科研网址导航|学术头条分468
-
《时代技术》投稿全攻略:一位审稿499
-
2025年国际期刊预警名单发布!600
-
2025年中科院期刊分区表重磅发3957
-
中科院已正式发布2024年预警期861
-
2025年度国家自然科学基金项目727
-
中国科协《重要学术会议目录(202733
-
2024年国家自然科学基金项目评1138
-
2024年JCR影响因子正式发布1214
-
吉林大学校长张希:学术会议中的提1391
-
SCI论文插图全攻略:从规范解析08-01
-
国际学术会议参加经验是怎么样的呢08-01
-
掠夺性会议是怎么进行判断的呢?—08-01
-
SCI论文投稿费怎么交?202408-01
-
中国政法大学证据科学研究院 20945

-
中国消防协会 21033
-
Global Science & 24171
-
武汉点歌机租赁公司 2143
-
中国光大银行 21067
-
中国能源学会 17877
-
受不鸟会展公司 22940
-
至远会务 22970
-
北京外国语大学 18099
-
大连理工大学 18326
-
黄山市富伟会议会展公司 24002
-
DME2011 1887
-
中国环境科学学会环境规划专业委员 23039
-
QSD 23102
-
北京鸿腾瑞达广告有限公司 17943
-
北京向阳科技 23261
-
中国生物医学工程学 20964
-
江苏省姓氏文化研究会 18022
-
香港机械工程师协会 2004
-
武汉红矮星传媒有限公司 7895



