















交叉信息研究院赵行课题组等提出新型符号性记忆框架ChatDB
2024/04/09
 475
475近期,清华大学交叉信息研究院赵行助理教授研究组及其合作单位的研究者们提出一种新型符号性记忆框架ChatDB,突破了此前常用的记忆框架中对储存信息操作不精确、历史信息储存形式缺乏结构性等局限。
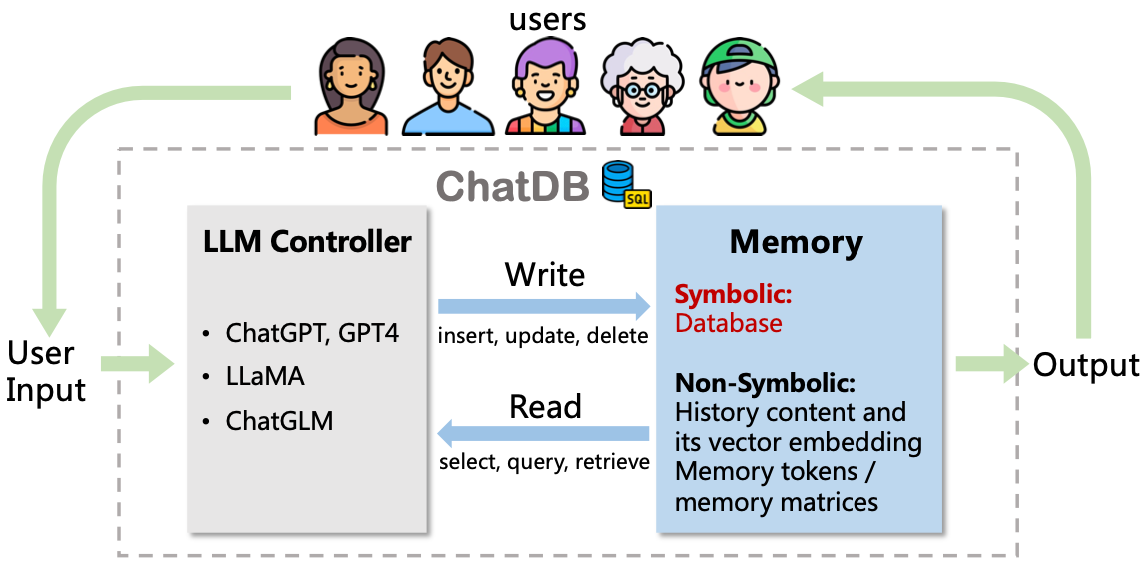
图1.ChatDB工作流程示意图
ChatDB由一个大语言模型(如ChatGPT)和一个数据库组成,可利用符号性操作(即SQL指令),实现对历史信息长期、精确的记录、处理和分析,并帮助回应用户的需求。其框架包含三个主要阶段:输入处理(input processing),记忆链(chain-of-memory),总结回复(response summary)。第一阶段,LLMs处理用户输入需求,对不涉及使用数据库记忆模块的指令,直接生成回复;而对涉及记忆模块的指令,则生成能与数据库记忆模块交互的一系列SQL语句。第二阶段,记忆链执行一系列中间记忆操作与符号性记忆模块交互。ChatDB按照先前生成的SQL语句依次执行插入、更新、选择、删除等操作。外部数据库执行相应的SQL语句,更新数据库并返回结果。在执行每一步记忆操作之前,ChatDB会根据先前SQL语句的结果决定是否更新当前记忆操作。第三阶段,语言模型综合与数据库交互得到的结果,并对用户的输入做出总结回复。
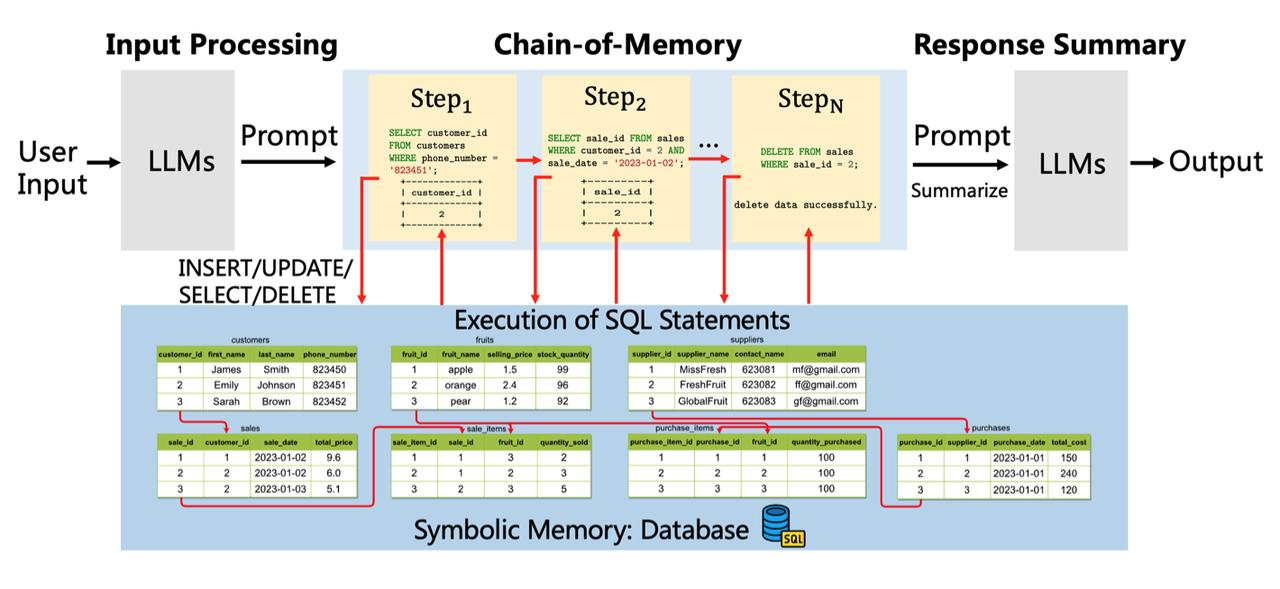
图2.ChatDB框架概览
为验证ChatDB中将数据库作为符号性记忆模块来增强大语言模型的有效性,并与其他的模型进行定量比较,研究者们构造了一家水果店运营管理的合成数据集,并命名为“水果商店数据集”,其中包含了70条按时间顺序生成的商店记录,约有3300个tokens(小于ChatGPT最大上下文窗口长度4096个)。这些记录包含水果店的四种常见操作:采购、销售、价格调整和退货。ChatDB模型中的LLM模块使用了ChatGPT(GPT-3.5 Turbo),温度参数设置为0,并使用MySQL数据库作为其外部符号性记忆模块。对比的基线模型为ChatGPT(GPT-3.5 Turbo),最大的上下文长度为4096,温度参数也设置为0。研究者们在水果商店问答数据集上进行了实验,发现相对于ChatGPT,ChatDB在这些问题的解答上展现出了显著的优势。
近日,该成果以论文“ChatDB:用数据库作为符号性记忆模块来增强大语言模型”(ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory)发布于康奈尔大学ArXiv。
该论文共同第一作者为清华大学交叉信息研究院博士生胡晨旭和智源研究院研究员付杰,通讯作者为付杰和交叉信息院助理教授赵行,其他作者包括清华大学博士生杜晨壮、骆思勉,以及浙江大学助理教授赵俊博。
文章来源清华大学新闻,分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。







-
2025年智能光子学与应用技术国际学 06-10

-
2025年8月优质学术会议推荐 589

-
2025年第十二届能源与环境研究国际 400
-
2025年机械工程,新能源与电气技术 559
-
2025年计算机科学、图像分析与信号 553
-
2025年材料化学与燃料电池技术国际 493
-
第七届精神病学国际大会(CP 202 08-01
-
第七届老龄化与老年医学国际学术会议( 08-01
-
第十四届心理学与健康国际学术研讨会( 08-01
-
第七届测绘与地理信息国际研讨会(CS 08-01
-
第七届大气与海洋科学国际研讨会(SA 08-01
-
第十一届地质灾害研究与防治国际学术会 08-01
-
第十六届地质和地球物理学国际会议(I 08-01
-
第七届细胞科学与再生医学国际研讨会( 08-01
-
第七届合成生物学与生物医学国际研讨会 08-01




































-
2025最新JCR分区及影响因子1939
-
好学术:科研网址导航|学术头条分468
-
《时代技术》投稿全攻略:一位审稿499
-
2025年国际期刊预警名单发布!600
-
2025年中科院期刊分区表重磅发3957
-
中科院已正式发布2024年预警期861
-
2025年度国家自然科学基金项目727
-
中国科协《重要学术会议目录(202733
-
2024年国家自然科学基金项目评1138
-
2024年JCR影响因子正式发布1214
-
吉林大学校长张希:学术会议中的提1391
-
SCI论文插图全攻略:从规范解析08-01
-
国际学术会议参加经验是怎么样的呢08-01
-
掠夺性会议是怎么进行判断的呢?—08-01
-
SCI论文投稿费怎么交?202408-01
-
中山市富兴塑胶异型材厂 20865

-
解放军总医院第一附属医院超声科 21122
-
北京航空航天大学 17911
-
大连市福佳集团 17891
-
上海优势商务咨询有限公司 20956
-
大连理工大学 23143
-
广医三院 21238
-
深圳市汉威展览策划有限公司 17938
-
中国石油大学(华东)化学化工学院 2040
-
广东省生物医学工程学会 2025
-
VFEAVW 7929
-
百奥泰国际会议有限公司 1904
-
武汉大学城市设计学院 22919
-
江苏无锡江南大学 24059
-
成都军区昆明总医院全军骨科中心 17914
-
中国石油化工有限公司济南分公司 17892
-
WILL 20891
-
中国科学院研究生院工程教育学院 23137
-
广州正和会展服务有限公司 22890
-
武汉千学信息咨询有限公司 8047



